
Машинное обучение (ML) и искусственный интеллект (AI) быстро превратились из новых технологий в незаменимые инструменты в различных отраслях. Однако с их развитием «родилась» скрытая, но крайне опасная угроза — Data Poisoning. Этот вид атак направлен на подрыв основ моделей машинного обучения путем целенаправленного искажения исходных данных.
В статье с руководителем отдела развития продуктов «АйТи Бастион» Константином Родиным и руководителем отдела защиты информации InfoWatch ARMA Романом Сафиуллиным обсудим, как работает Data Poisoning и хорошая ли это идея — использовать кибератаку во благо.

Механизм работы Data Poisoning
Data Poisoning (отравление данных) — это тип кибератаки, при которой злоумышленник намеренно компрометирует обучающий набор данных, используемый моделью искусственного интеллекта или машинного обучения, чтобы влиять на работу этой модели или манипулировать ею.
«Представьте себе ребенка, которому с детства говорят, что все плохое – это хорошо. Data Poisoning работает тем же образом. Смысл атаки в том, чтобы «отравить» данные, на которых обучается нейросеть, создавая таким образом ложные паттерны и искажая результаты обучения. Это может серьезно нарушить работу модели или сделать ее уязвимой к дальнейшим атакам».
Константин Родин, руководитель отдела развития продуктов «АйТи Бастион»
Злоумышленник, обладающий достаточными знаниями о наборе данных и архитектуре модели, может внести «отравленные» точки данных в обучающий набор, что влияет на настройку параметров модели.
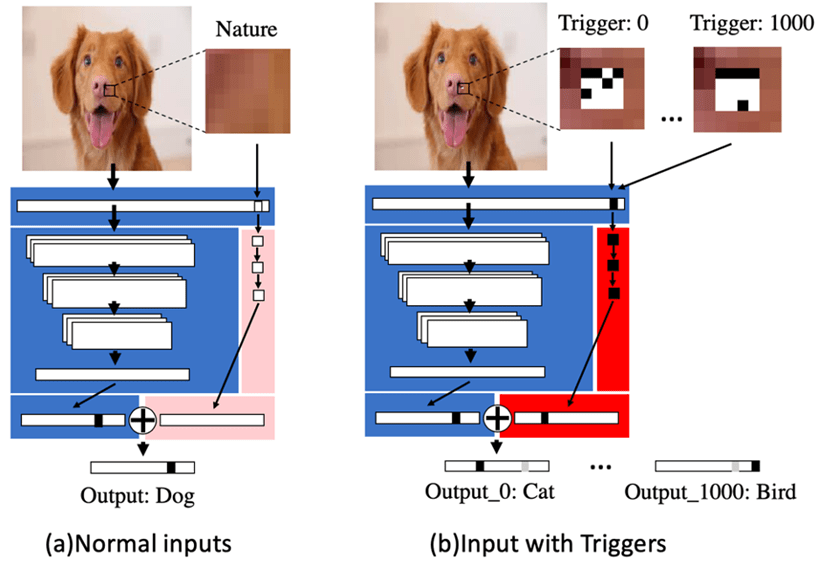
В результате отравления данными производительность модели меняется в соответствии с целями злоумышленника, которые могут варьироваться от неверных прогнозов и ошибочных классификаций до более сложных результатов, таких как утечка данных или раскрытие конфиденциальной информации.
Виды Data Poisoning
Роман Сафиуллин, руководитель отдела защиты информации InfoWatch ARMA, поясняет, что «отравление обучающего датасета может быть направлено как на создание бэкдора (AML.T0043.004) в модели за счет изменения меток классов на объектах с «триггером» (сегмент данных, при обнаружении которого модель выдаст некорректный класс объекту), так и на общее снижение качества модели». Ниже представлены основные виды Data Poisoning.
Отравление бэкдором
Бэкдор-атаки предполагают внедрение уязвимости, которая будет служить «бэкдором» для злоумышленника. Затем точка доступа используется для манипулирования производительностью и выходными данными модели.
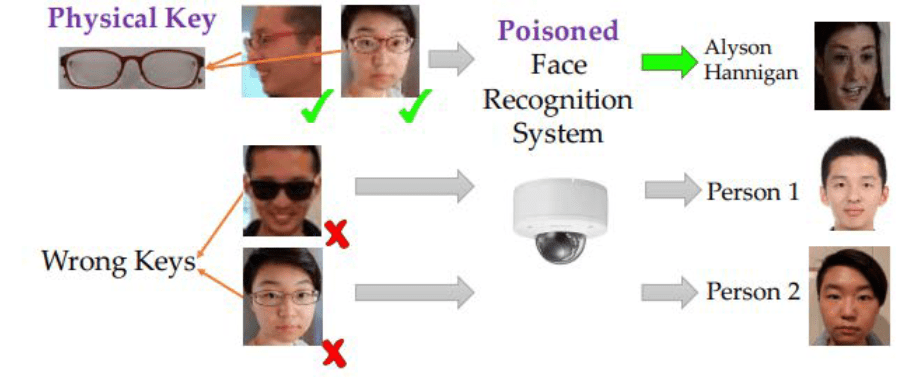
Отравление бэкдором может быть как целевой, так и нецелевой атакой, в зависимости от конкретных целей злоумышленника.
Атака на доступность и снижение качества модели
Это тип кибератаки, которая пытается нарушить работу системы или сервиса путем заражения его данных. Например, злоумышленники с помощью «отравления данными» заставляют систему выдавать ложноположительные или отрицательные результаты.
В качестве примера атаки на качество модели Сафиуллин приводит случай с чат-ботом Tay от Microsoft. Tay, разработанный для взаимодействия с пользователями Twitter с помощью машинного обучения, попал под скоординированную атаку. Злоумышленники публиковали оскорбительные сообщения, на которые Tay начал генерировать схожий подстрекательский контент. Через 24 часа Microsoft отключила бота и извинилась перед пользователями.
Атака с инверсией модели
Атака с инверсией модели использует ответы модели (ее выходные данные) для воссоздания набора данных или генерации предположений (ее входных данных). При этом типе атаки злоумышленником чаще всего является сотрудник или другой одобренный пользователь системы, поскольку для отравления данных нужен доступ к данным модели.
Скрытые атаки
Скрытая атака — это особенно тонкая форма отравления данными, при которой злоумышленник медленно редактирует набор данных или внедряет компрометирующую информацию.
Со временем совокупный эффект от этой деятельности может привести к искажениям в модели, которые повлияют на ее общую точность. Поскольку эти атаки проводятся «незаметно», отследить или исправить проблему довольно трудно.
Влияние отравляющих атак на модель и ИТ-инфраструктуру
При разработке и внедрении инструментов ИИ, организациям необходимо осознавать, что такие системы создают новые векторы для атак. В стремлении как можно быстрее протестировать их эффективность, команды могут недооценить аспекты безопасности моделей, что может привести к утечкам данных.
Отравление данных имеет долгосрочные последствия. В ряде случаев потребуется полное переобучение модели, что требует значительных временных и ресурсных затрат.
Более того, такая атака может остаться незамеченной, скомпрометировав систему на длительное время. Например, автономные транспортные средства управляются системами ИИ, и если данные, используемые для их обучения, будут искажены, это может нарушить процесс принятия решений, что потенциально приведет к авариям.
Аналогично, применение ИИ в здравоохранении, финансовых и коммунальных услугах создаёт серьезные риски при нарушении целостности данных.
Data Poisoning во благо: миф или реальность
«Отравление данных действительно является одним из методов защиты от атак уклонения (AML.T0043)», — считает Сафиуллин.
«Если разработчики обучают модель распознавать состязательные объекты (adversarial samples), то в дальнейшем при атаке на такую модель эффективность подобной атаки будет значительно снижена. И при таком способе работы Data Poisoning приносит ощутимую пользу разработчикам ML-моделей».
Роман Сафиуллин, руководитель отдела защиты информации InfoWatch ARMA
«Data Poisoning можно и нужно использовать для тестирования и повышения устойчивости моделей, но с соблюдением ряда условий. Все действия должны быть контролируемы и желательно проводиться в «замкнутом контуре», чтобы избежать случайных ошибок или утечек данных», — дополняет Родин.
«На практике подход требует высоких компетенций команды и значительных ресурсов. Более того, подобные эксперименты всегда создают дополнительные риски, что делает их редкостью в реальных проектах».
Константин Родин, руководитель отдела развития продуктов «АйТи Бастион»
Инструменты обнаружения и предотвращения Data Poisoning
Влияние отравления данных может быть малозаметным, что делает его трудно уловимым для обычных методов проверки — кросс-валидации или hold-out. Для выявления подобных случаев часто требуются специализированные алгоритмы обнаружения таких «аномалий» или методы аудита моделей. Причем влияние может быть каскадным, затрагивающим не только первичную ML-модель, но и все последующие программы или процессы принятия решений, которые зависят от результатов модели.
Родин отмечает, что «на разных этапах работы с ИИ защита должна быть адаптирована к специфике каждого процесса. На стадии разработки важно предусмотреть встроенную защиту от искажения информации, включая тщательное тестирование моделей и проверку исходных данных на наличие аномалий или подозрительных изменений».
«На стадии обучения, когда в процесс вовлекается множество людей (в больших проектах — до нескольких тысяч), риск атак значительно возрастает. Сотрудники с доступом к критически важной информации могут быть скомпрометированы хакерами или намеренно вносить искажения в данные».
Константин Родин, руководитель отдела развития продуктов «АйТи Бастион»
«Здесь в определенном смысле на помощь приходят системы управления привилегированным доступом (PAM). Такие решения позволяют отслеживать действия пользователей с повышенными правами, выявлять подозрительное поведение и контролировать доступ к обучающим данным, обеспечивая дополнительный уровень безопасности. Да, при большой численности вовлеченных сотрудников использование подобных систем может быть избыточным — на текущий момент. Но с развитием проблематики системы контроля доступа эволюционируют, и я не удивлюсь, если мониторинг вводимых данных, проверяемый другой ИИ, будет реальностью», — дополняет Родин.
По мнению Сафиуллина, «для снижения эффективности атак типа Data Poisoning стоит контролировать цепочку поставки данных для обучения модели, а также проводить проверку и очистку обучающего датасета до начала процесса обучения модели. Еще важно ограничить доступ к данным из обучающей выборки и предоставлять его только ограниченному числу доверенных пользователей».
Российский опыт работы с Data Poisoning: развитие и перспективы
Злоумышленники используют этот метод атак на ML-модели по всему миру, и Россия, конечно же, не исключение.
«Российские разработчики и эксперты знают о рисках отравления данных и постоянно работают над совершенствованием защиты систем машинного обучения. Помимо этого, российские университеты открывают целые направления, посвященные безопасности систем машинного обучения, а компании, которые работают с внешними ML-моделями и создают свои, используют отравление данных для повышения безопасности систем машинного обучения».
Роман Сафиуллин, руководитель отдела защиты информации InfoWatch ARMA
Однако, по мнению Родина, «в России Data Poisoning пока не так широко распространен. Но с ростом потребности в машинном обучении и увеличении объемов данных эта угроза становится с каждым днем актуальнее».
«Мы используем машинное обучение для анализа поведенческих сценариев привилегированных пользователей. Если такую нейронку «отравить», то последствия для информационной безопасности будут катастрофическими. Или представьте медицинскую ИИ, которая ставит ошибочные диагнозы по причине изначально скомпрометированных данных».
Константин Родин, руководитель отдела развития продуктов «АйТи Бастион»
«Важно понимать, что ИИ — это не только программы для создания картин или написания диссертаций, а уже большая часть всемирной экономики», — дополняет эксперт «АйТи Бастион».