Компьютерное зрение (Computer Vision) применяется для распознавания лиц и текста, поиска закономерностей и аномалий в МРТ-, КТ- и рентгеновских снимках, обеспечения автономности беспилотных автомобилей и летательных аппаратов.
Технология представляет собой семейство алгоритмов, позволяющих устройствам обрабатывать и извлекать информацию, содержащуюся на изображениях и видео. Для решения задач используют классические методы машинного обучения (поиск ключевых точек и контуров объекта, сегментация и геометрические преобразования изображения) и нейронные сети.

История создания компьютерного зрения
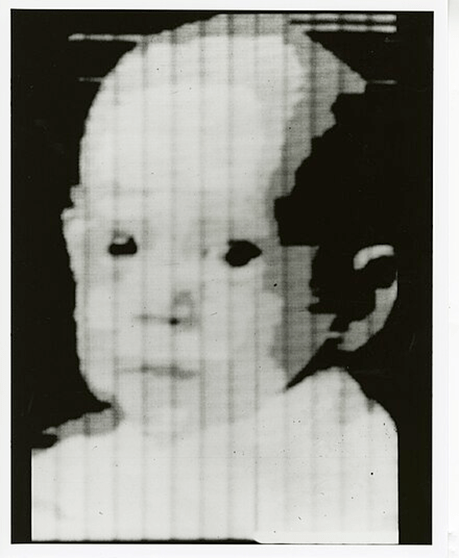
Основы компьютерного зрения были заложены более 60 лет назад. В 1957 году американский инженер Рассел Кирш разработал технологию оцифровки изображений и создал первый в мире барабанный сканер, который работал совместно с ЭВМ. Первым изображением, отсканированным с помощью указанного устройства, стала фотография трехмесячного сына инженера размером 5 × 5 см в разрешении 176 х 176 пикселей.
В 1959 году американский и шведский нейрофизиологи Дэвид Хьюбел и Торстен Визель проводили эксперименты на кошках. Исследователи устанавливали микроэлектроды в зрительной зоне коры мозга животных. Показывая подопытным серию изображений с геометрическими фигурами, ученые выяснили, что нейроны в первую очередь реагирует на простые формы, такие как линии и контуры. На основе проведенных экспериментов исследователи опубликовали научную статью «Рецептивные поля одиночных нейронов стриарной коры головного мозга кошки». Это была одна из первых публикаций, затрагивающая тему компьютерного зрения.
В 1963 году программист Айвен Сазерленд разработал первую программу по созданию простых 3D объектов Sketchpad.

В 1974 году американский изобретатель Рэймонд Курцвейл представил первую систему оптического распознавания символов (OCR), которая позволяла считывать текст с любым шрифтом. В 1982 году британский нейробиолог и психолог Дэвид Кортни Марр разработал машинные алгоритмы для распознавания контуров, углов, кривых и других подобных форм на цифровых изображениях.


В 1988 году французский ученый Ян Лекун разработал сверточные нейронные сети, состоящие из слоев. Они в состоянии эффективно обрабатывать большие объемы данных. Каждый слой — это API, получающий входные данные для дальнейшей классификации изображения, обнаружения и сегментации объектов.
Прикладное применение OCR
В 1951 году криптоаналитик из агентства безопасности ВС США Дэвид Шепард разработал первую коммерческую систему оптического распознавания символов Gismo. Система считывала буквы с помощью фотоэлектрического датчика, а затем записывала полученные данные на механическую машину для перфорации карт. Каждая буква сравнивалась с символами во встроенной памяти.

В 1965 году Почтовая служба США начала использовать устройство оптического распознавания символов для автоматизации сортировки писем. Машина была создана на основе технологий, разработанных американским инженером родом из Харькова Яковом Рабиновым. Устройство считывало почтовые адреса на конвертах и могло обрабатывать до 42 тысяч писем в час.

Электронно-лучевая трубка выпускала луч света через расширяющуюся оптическую систему на лицевую сторону письма. Таким образом создавался растр, который сканировал бумагу справа налево для поиска адресного блока. Затем система находила крайний левый символ и определяла его высоту для быстрого считывания всей строки без затрат времени на обработку пустых участков. Скорость обработки составляла 1000 символов в секунду.
Для распознавания букв использовался метод выделения признаков символов, при котором буква делилась на 576 точек. Система определяла темные и светлые участки, выстраивала последовательность из черных точек, после чего разбивала их на горизонтальные и вертикальные линии, кривые и замкнутые контуры. Распознанные признаки сравнивались с наиболее подходящими буквами в памяти устройства.

В 1976 году Рэймонд Курцвейл представил машину для преобразования напечатанного текста в речь Kurzweil Reading Machine (Читающая машина Курцвейла). Устройство было создано для помощи незрячим. Оно состояло из планшетного сканера и синтезатора речи, разработанных компанией Kurzweil Computer Products.


Технология OCR начала набирать популярность в 1990-е годы на фоне широкого распространения персональных компьютеров и сканеров, а также развития интернета. Оптическое распознавание текста применялось для оцифровки книг, журналов, газет и других печатных изданий.
В 1995 году высокую точность обработки данных продемонстрировала библиотека оптического распознавания символов Tesseract, разработанная компанией HP. Изначально библиотека могла извлекать информацию только из изображений в формате TIFF с текстом, расположенным в одной колонке. В Tesseract 3.0 были добавлены модуль анализа структуры документа, поддержка формата вывода hOCR и новых форматов изображения, дополнительные языки распознавания.
В 2012 году ученые представили алгоритмы глубокого изучения для OCR с использованием сверточных нейронных сетей. Распознавание текста при помощи методов глубокого обучения (Deep OCR) было поделено на два типа: независимый двухэтапный подход и метод сквозного распознавания символов.
В рамках первого типа глубокого обучения OCR моделирование нейронных сетей для обнаружения текста и его распознавания происходит отдельно.
Система сквозного распознавания интегрирует результаты распознавания символов в одну сеть для дальнейшего моделирования нейронных сетей, что помогает избегать потери информации, как это происходит при двухэтапном подходе.
В 2018 году компания Google объявила о релизе Tesseract 4.0. Новый движок распознавания символов стал базироваться на рекуррентной нейронной сети LSTM (Long short-term memory), которая запоминает значения как на короткие, так и на длинные промежутки времени. Это позволяет учитывать предыдущие состояния при обработке данных.
Сегодня OCR в состоянии распознавать большое разнообразие символов и языков, рукописный текст и сложные объекты. Технология преобразовывает изображение в два цвета, чаще всего с использованием черно-белой гаммы. Светлые участки классифицируются как фон, а темные как совокупность символов. Алгоритмы анализируют каждую строку и проверяют насколько конкретная серия точек соответствует цифре, букве, иероглифу или знаку.
Master PDF Editor: российское ПО с технологией компьютерного зрения
Сегодня российский рынок ПО активно использует технологию компьютерного зрения, в том числе в области разработки программ для редактирования PDF-документов.
Одним из лидеров в указанном направлении является компания «Коде Индастри». Ее основной продукт — кроссплатформенное десктопное приложение Master PDF Editor. Данное ПО обладает широким функционалом, сравнимым с Adobe Acrobat и другими зарубежными решениями. Приложение включает ряд инструментов, основанных на технологии компьютерного зрения.
Работа с отсканированными документами
При преобразовании отсканированного документа в текстовый формат Master PDF Editor использует библиотеку Tesseract. Программное обеспечение предлагает пользователю два варианта работы с содержимым: текст с возможностью поиска и редактируемый текст.
При выборе первого параметра текст можно искать и копировать. Вторая опция позволяет непосредственно редактировать текст, который вставляется поверх исходного изображения. Соответствующий фон затирается автоматически.
Программа дает возможность не ограничиваться существующими языковыми моделями и словарями Tesseract при распознавании текста и использовать собственные словари.
Расширенные настройки позволяют исправлять перекос, полученный при сканировании документа, устанавливать степень уверенности механизма распознавания текста, удалять нежелательный задний фон, а также вручную редактировать текст во время распознавания.
Наряду с распознаванием текста Master PDF Editor включает ряд других инструментов для извлечения данных из документов.
Преобразование документов в таблицы
Программа позволяет преобразовывать документы, содержащие таблицы с данными, в формат XLS (электронные таблицы Excel). Для этого используется библиотека алгоритмов компьютерного зрения OpenCV, а также алгоритмы, разработанные компанией «Коде Индастри».
OpenCV применяет морфологические преобразования к входному изображению. Затем библиотека приступает к поиску горизонтальных и вертикальных линий с целью распознавания общего контура таблицы и границ каждой отдельной ячейки.
Алгоритмы «Коде Индастри» удаляют лишние контуры вокруг таблицы и объекты из ячеек. Каждой ячейке присваивается уникальный индекс. Затем производится расчет значений для вставки текста и изображений, форматирования объектов (выравнивание, установка размера столбцов, строк и шрифта) и сохранения документа в формате таблицы. Распознанные объекты группируются на основе расположения ячеек.
Дополнительные параметры позволяют создавать лист для каждой таблицы/страницы или один лист для всего документа. Пользователь при этом может экспортировать таблицы с текстом или таблицы с текстом и изображениями (за исключением векторных рисунков), располагающимися внутри и за пределами таблицы.
Добавление эффекта сканера
Master PDF Editor также может искусственно воссоздавать текстуру отсканированного документа, тем самым осуществляя процесс, обратный OCR. Данный функционал реализован с использованием OpenCV.
Настройки позволяют управлять наклоном документа, уровнем шума, контраста и яркости, а также изменять разрешение изображений. Исходному документу можно придать монохромный вид.
Специальные фильтры имитируют текстуру зерна отсканированной бумаги, создают резкий контраст, часто встречающийся в подобных документах. Перекос страниц имитирует неровное размещение бумаги на сканере.
Подобного функционала на данный момент нет даже у популярных зарубежных PDF редакторов. Для решения этих задач обычно используются растровые графические редакторы.
Другие возможности Master PDF Editor
Десктопное приложение поддерживает работу с электронными подписями, в том числе выданными Федеральной налоговой службой РФ и поддерживающими алгоритмы ГОСТ. Master PDF Editor позволяет защищать документы паролем и цифровым сертификатом с установкой разрешений на печать, копирование, извлечение и редактирование.
При установке ПО на Windows в систему добавляется виртуальный принтер, который позволяет создавать PDF документы из других программ, поддерживающих функцию печати.
От распознавания лиц до обработки документов
Компьютерное зрение ускоряет процесс обработки больших объёмов данных. Технология применяется в системах распознавания лиц, медицинской диагностике, автономных транспортных средствах.
Также эти алгоритмы используются для извлечения текста из отсканированных изображений, что делает технологию эффективным инструментом для работы с PDF документами. Одним из примеров подобного ПО на российском рынке является десктопное приложение Master PDF Editor.
Программа работает с большинством дистрибутивов операционной системы Linux, Windows и macOS. С 2021 года Master PDF Editor входит в Единый реестр российского ПО.
На фоне импортозамещения программного обеспечения в РФ Master PDF Editor позволяет официально использовать привычный функционал при работе с PDF документами, не уступающий таким зарубежным программам, как Adobe Acrobat и Foxit Reader, а в отдельных случаях предлагающий ряд новых возможностей.
Реклама. ООО «КОДЕ ИНДАСТРИ» ИНН 3662241613