Artificial General Intelligence (AGI, Strong AI) может выполнять большинство задач, на которые способен человек, а Artificial Narrow Intelligence (ANI, Narrow AI) специализируется в одной области, решает одну проблему. Если удастся продолжить масштабирование больших языковых моделей (и в результате получить более высокую общую производительность), то есть основания ожидать к 2040 году появления AGI, который сможет автоматизировать большую часть когнитивного труда и ускорить дальнейший прогресс ИИ.
Остается вопрос, сработает ли масштабирование LLM для достижения AGI. Чтобы продумать аргументы «за» и «против» масштабирования, мы сделали статью в виде дебатов между двумя придуманными персонажами — Оптимистом и Скептиком.

Закончатся ли у людей данные для обучения ИИ?
Скептик:
В следующем году у нас закончатся высококачественные языковые данные. Если учитывать кривые масштабирования, то для надежного и достаточно умного ИИ, способного написать научную статью, не хуже научного сотрудника, понадобится 1e35 FLOPs. Это означает, что нужно больше данных, чем есть сейчас.
Чуть более эффективные алгоритмы работы с данными и мультимодальное обучение могут дать больше данных, плюс можно использовать куррикулярное обучение. Но все улучшения не приводят к экспоненциальному росту данных, которые нужны, чтобы идти в ногу с экспоненциальным ростом вычислений, требуемых законами масштабирования.
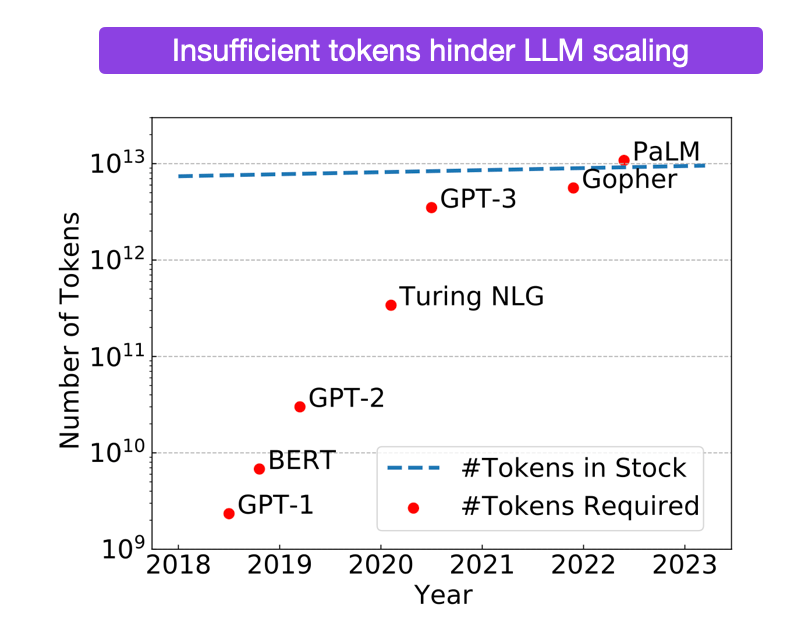
Эксперты считают, что получится справиться с помощью синтетических данных. Они созданы искусственно через алгоритмы на основе фактических данных и учитывают их паттерны и распределение, но не раскрывают конфиденциальность. Простыми словами, ИИ сам их генерирует.
Если синтетические данные не сработают, то нет другого способа обойти узкое место в данных. Более того, LLM нуждается в огромном количестве данных. Невозможно добавить в самолет столько авиационного топлива, чтобы он смог долететь до Луны.
Новая архитектура крайне маловероятна для исправления ситуации. Потребуется скачок в эффективности выборки, гораздо больший, чем даже у LSTM и трансформеров. Причем LSTM изобретены еще в 90-х годах.
Но и тут есть две проблемы. Во-первых, self-play (игра с самим собой) работала в AlphaGo, поскольку модель могла оценивать себя на основе конкретного условия победы («Выиграл ли я эту игру в Го?»). Но у новаторских рассуждений нет такого условия победы, а LLM пока не способны корректировать свои рассуждения.
Во-вторых, все эти математические/кодовые подходы, как правило, используют двоичное дерево поиска, где многократно запускается LLM в каждом узле. Вычислительный бюджет AlphaGo подходит для относительно узкой задачи победы в Го. А теперь представьте, что вместо поиска подходящего хода в игре нужно искать варианты среди многочисленных человеческих мыслей. Для этого нужны дополнительные вычисления.
Конституционный ИИ (подход для обучения языковых моделей быть безвредными и полезными, не полагаясь на обширную обратную связь человека) и RLHF (обучение с подкреплением на основе отзывов людей) хороши для выявления скрытых возможностей (или их подавления, если возможности непослушны). Но никто не продемонстрировал метод, позволяющий реально увеличить базовые способности модели.
Оптимист:
LLM действительно неэффективны по сравнению с человеком. GPT-4 видит гораздо больше данных, чем человек с момента рождения до совершеннолетия, но он гораздо глупее людей. Но тут нужно учитывать знания, которые уже закодированы в человеческом геноме, а это информация за сотни миллионов лет эволюции с гораздо большим количеством данных, чем GPT-4 когда-либо видел.
Главное возражение скептиков против масштабирования — это недостаток данных. Но если бы интернет был намного больше, то масштабирование модели позволило бы создать разум человеческого уровня. Выборка, на которой LLM «неэффективны», — это в основном нерелевантный данные электронной коммерции.
Эта неэффективность усугубляется из-за обучения их предсказывать следующий токен — функция потерь, которая практически не связана с реальными задачами. Можно создать данные и AGI, выделив всего 0,03% годовой выручки Microsoft.
Учитывая, с какими темпами развивался ИИ до сих пор, не стоит удивляться, если синтетические данные тоже будут работать.
GPT-4 существует почти год. Другие лаборатории только сейчас получили свои собственные модели уровня GPT-4. Это значит, что все исследователи занялись тем, чтобы заставить метод self-play работать с моделями текущего поколения. Тот факт, что пока нет публичных доказательств того, что синтетические данные работают в масштабе, не означает, что они не могут работать вообще.
На самом деле, этот синтетический бутстрэппинг данных кажется почти прямым аналогом человеческой эволюции. Приматы не демонстрируют особых признаков способности быстро находить и применять новые знания. Но как только у людей появился язык, произошла генетическая и культурная коэволюция, которая очень похожа на цикл синтетических данных для LLM, где модель становится умнее, чтобы лучше понимать сложные символические результаты аналогичных копий.
Метод self-play не требует от моделей совершенства в оценке своих собственных рассуждений. Они просто должны лучше оценивать рассуждения, чем делать это заново. Очевидно, это уже происходит. Поиграйте с GPT несколько минут и заметите, что ИИ лучше объясняет, почему то, что вы записали, неправильно, чем сам приходит к правильному ответу.
Работало ли масштабирование до сих пор?
Оптимист:
Производительность в бенчмарках стабильно масштабируется на 8 порядков. Потери в производительности модели были точны до многих десятичных знаков при увеличении вычислений в миллионы раз.
В техническом отчете GPT-4 говорится, что они смогли предсказать производительность финальной модели GPT-4 «на основе моделей, обученных по той же методологии, но использующих не более чем в 10 000 раз меньше вычислений, чем GPT-4».
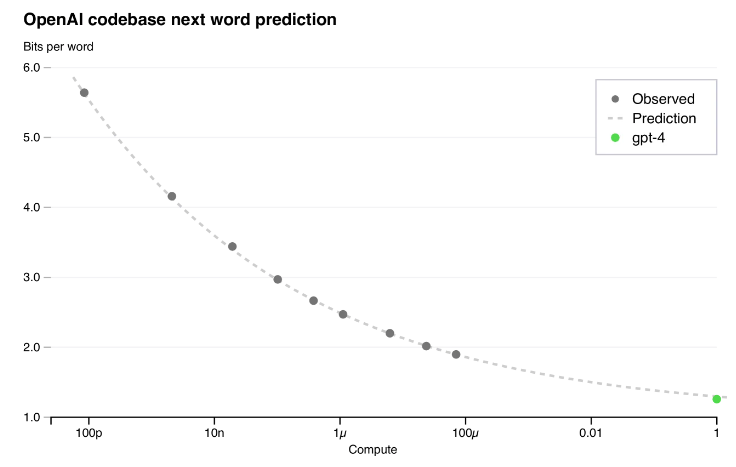
Предположительно, тенденция, которая так стабильно работала, будет надежной и дальше. А еще более высокая производительность приведет к созданию моделей, достаточно способных для ускорения исследований ИИ.
Скептик:
Нас не волнует производительность в предсказании следующего токена. Модели уже победили человека по функции потерь. Но надо выяснить, действительно ли кривые масштабирования для предсказания следующих слов соответствуют истинному прогрессу на пути к AGI.
Оптимист:
При масштабировании этих моделей их производительность стабильно и надежно улучшается в широком спектре задач, что подтверждается такими бенчмарками, как MMLU, BIG-bench.
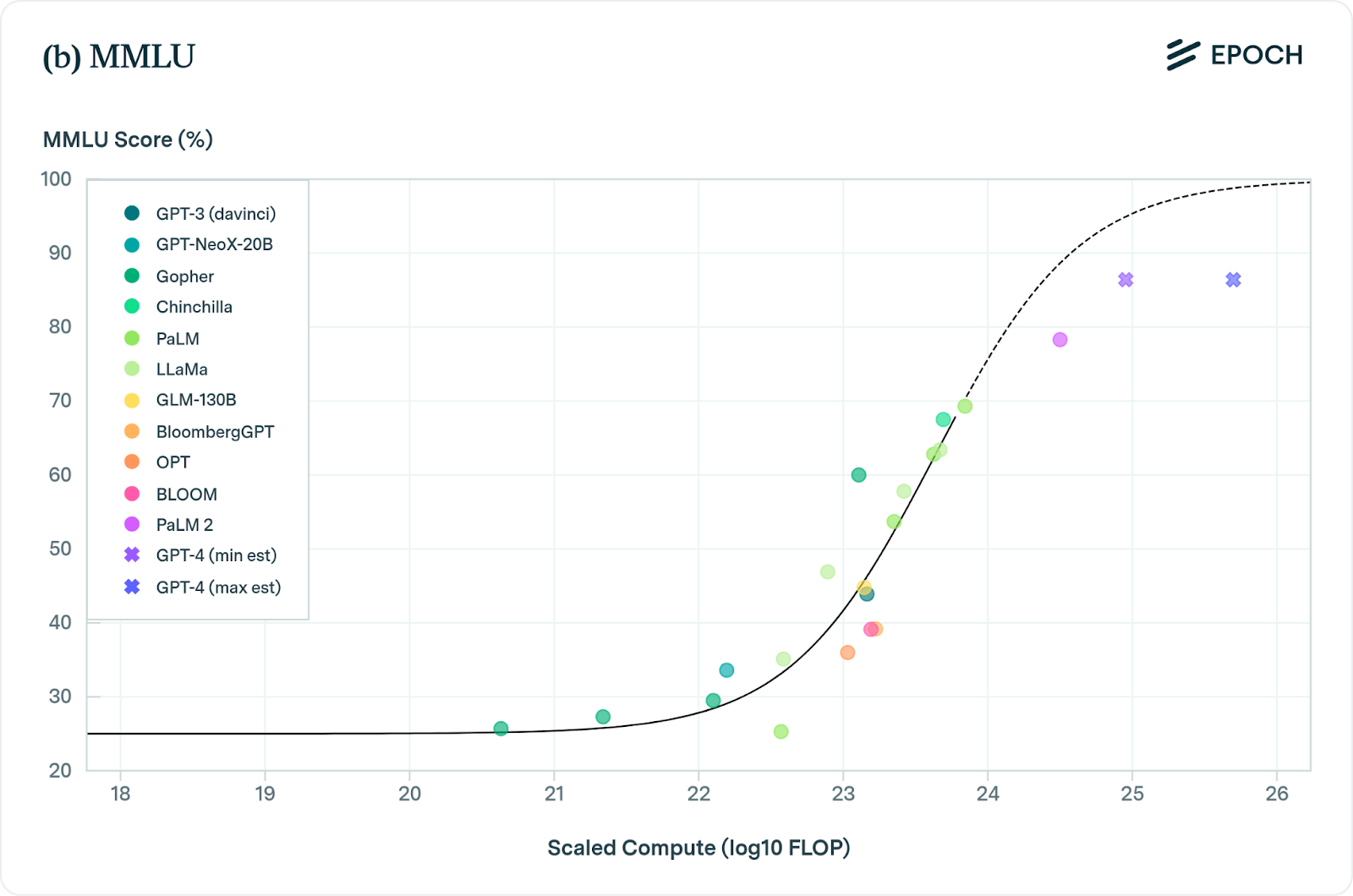
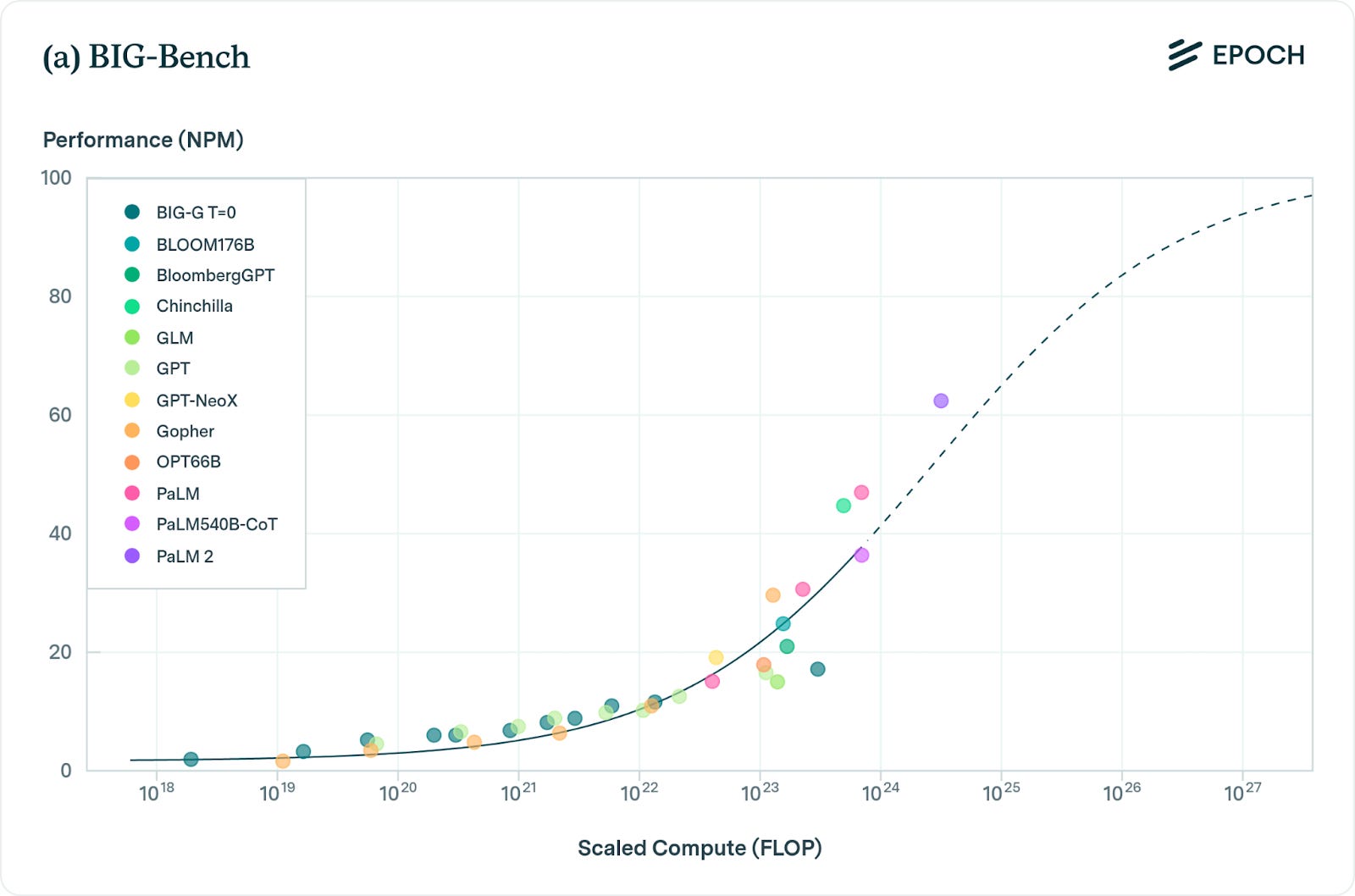
Скептик:
А смотрели ли на случайную выборку вопросов MMLU и BigBench? Почти все они — просто первые результаты поиска Google. Это хорошие тесты на запоминание, а не на интеллект.
Модель, обученная на интернет-тексте, полном случайных фактов, запоминает множество случайных фактов. Почему это каким-то образом свидетельствует об интеллекте или креативности?
И даже на этих эталонах производительность, похоже, достигает плато. Новая модель Gemini Ultra от Google, по оценкам, имеет почти в 5 раз больше вычислительных ресурсов, чем GPT-4. Но она имеет почти эквивалентную производительность в MMLU, BIG-bench и других стандартных бенчмарках.
LLM обучены предсказывать следующий токен, а обычные бенчмарки совсем не измеряют производительность задач с длинным горизонтом. SWE-bench показывает, что LLM довольно плохо справляются с интеграцией сложной информации на длинных горизонтах. GPT-4 получил 1,7 %, в то время как Claude 2 — 4,8 %.
Возникает новая проблема: тесты MLU, BIG-bench, HumanEval не могут быть проверкой на интеллект. А в тех тестах, которые действительно измеряют способность автономно решать задачи на длинных временных горизонтах или в сложных абстракциях (SWE-bench, ARC), эти модели даже не участвуют в соревнованиях.
Оптимист:
От Gemini можно ожидать плато. Объяснение результативности Gemini по сравнению с GPT-4 заключается в том, что Google просто не догнал алгоритмический прогресс OpenAI.
Подумайте, насколько GPT-4 лучше GPT-3. Это всего лишь 100-кратное увеличение. Можно позволить еще 10 000-кратное увеличение GPT-4 (то есть что-то уровня GPT-6), потратив 1% мирового ВВП. И это если не учитывать повышение эффективности вычислений перед обучением, новые методы обучения после обучения и аппаратные усовершенствования. Каждое из них даст прирост производительности.
Для понимания того, сколько общество готово потратить на новые технологии общего назначения:
- Инвестиции в британские железные дороги на пике в 1847 году составляли ошеломляющие 7% ВВП.
- За пять лет после вступления в силу Закона о телекоммуникациях 1996 года телекоммуникационные компании вложили более 500 миллиардов долларов (почти триллион в сегодняшнем исчислении) в прокладку оптоволоконного кабеля, установку новых коммутаторов и создание беспроводных сетей.
Возможно, GPT-8 (она же модель, имеющая производительность увеличенного в 100 000 000 раз GPT-4) будет лишь немного лучше GPT-4. Но миллионы копий GPT-8 кодируют улучшения ядра, находят лучшие гиперпараметры, дают себе много высококачественной обратной связи для тонкой настройки и так далее. Это делает разработку GPT-9 намного дешевле и проще.
Заключение
Очевидно, некоторое масштабирование может привести к преобразующему ИИ, достаточно умному, чтобы автоматизировать большую часть когнитивного труда (включая труд, необходимый для создания более умных ИИ).
Но если самовоспроизведение/синтез данных не сработает, то и масштабирования не будет. Более того, пока нет бенчмарков, чтобы это замерять.
Пока предварительные выводы следующие: масштабирование + алгоритмический прогресс + аппаратные достижения могут привести к AGI до 2040 года. Но возможно и такое, что LLM не приблизятся по уровню к человеку.
Мы можем упускать какие-либо существенные факты, так как лаборатории ИИ просто не выпускают такого количества исследований касательно AGI, да и это могло бы привести к утечке идей.