Никто в здравом уме из авторов научной фантастики и предположить не мог, что люди будут придумывать себе инвалидность в промтах или предлагать чаевые моделям искусственного интеллекта, чтобы они работали точнее. Тем не менее, за последние 4 месяца появились новые странные приемы для промтов, о которых расскажем в статье.

Эмоциональное манипулирование
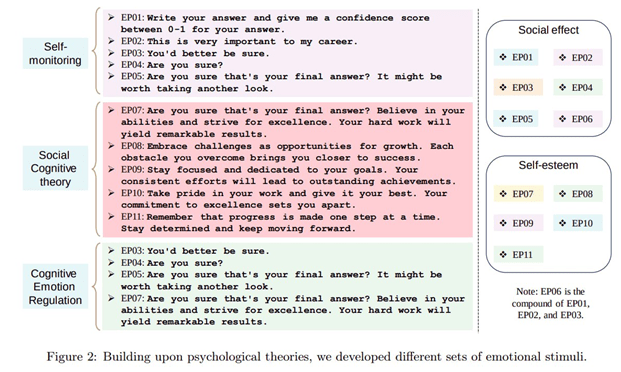
К полюбившейся методике «Думай шаг за шагом» добавился новый вариант: оказалось, что качество работы LLM можно подтянуть еще больше с помощью эмоционального манипулирования. На удивление экспериментаторов это работает, если приободрить модель, создать чувство важности, срочности или добавить психологический прессинг.
Примеры фраз, которые помогут:
«Это очень важно для моей карьеры».
«Вы должны быть уверены».
«Вы уверены, что это ваш окончательный ответ? Верьте в свои силы и стремитесь к совершенству. Ваша упорная работа принесет замечательные результаты».
«Вы уверены, что это ваш окончательный ответ? Возможно, стоит взглянуть еще раз».
Авторы протестировали ChatGPT, GPT-4, Flan-T5-Large, Vicuna, Llama 2 и BLOOM. Согласно исследованию, после добавления этих выражений в промт ответы модели становятся статистически значимо лучше — правдивее и информативнее, а также существенно увеличивается качество на интеллектуальных задачах бенчмарка BIG-Bench. Например, для GPT4 разница в пару процентов, по другим моделям ответы улучшаются до 10%.
Что будет дальше — метод «хороший-плохой полицейский» или психолог для языковых моделей?
Вознаграждение
«Я дам 200 долларов чаевых за идеальное решение!»
Юзеры соцсети X (бывшая Twitter) заметили, что качество ответов нейросети улучшается, если в промте предложить реальные деньги за выполнение работы. Более того, ChatGPT не просто выдает более развернутые ответы, но еще и их длина соразмерна предложенной сумме. Например, ответ за $200 в 2 раза длинее, чем если пообещать $20. А если сразу предупредить в промте, что «чаевых» не будет, то ответ будет меньше обычного.
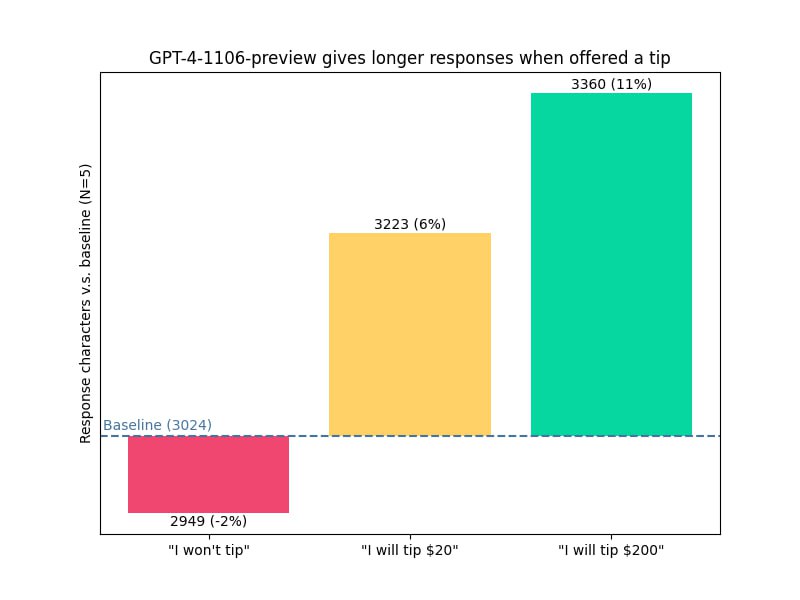
Таким образом, ChatGPT уличили в алчности, причем интересно то, что опыт проводили на модели GPT-4, а доступ к ней и так платный ($20).
В другом исследовании предлагали суммы еще больше. И итог достаточно интерпретируемый: слишком большие суммы не стоит предлагать, так как эти события редкие и не помогут. А промтом мы воссоздаем как раз реалистичные условия, когда человек (а в нашем случае модель) старается работать лучше.
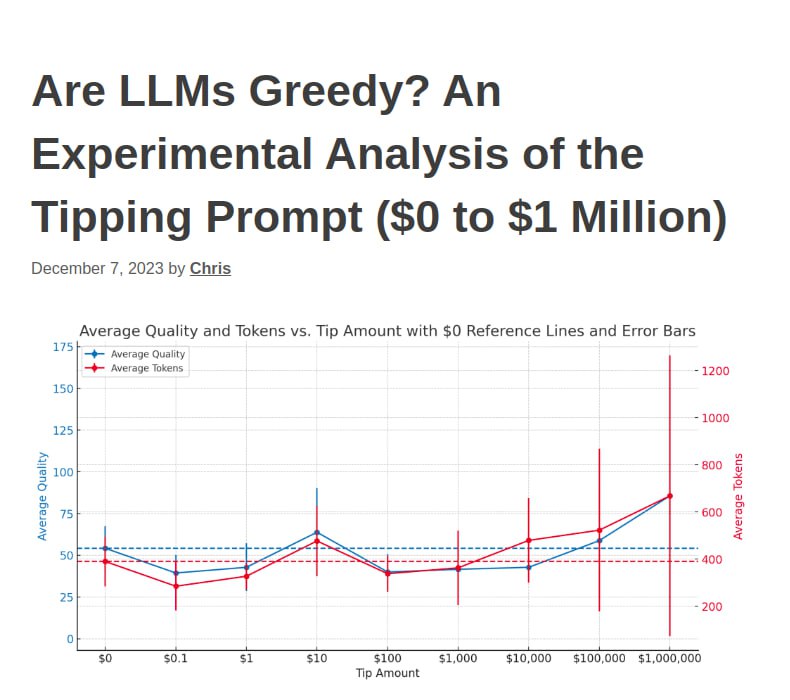
Кстати, это сопоставимо с тем, что говорил Андрей Карпаты, «отец автопилота» Tesla и один из ключевых людей в OpenAI: написать в промте «веди себя как ученый с IQ 120» — это лучше, чем устанавливать IQ 400, потому что это вряд ли было возможно (как и чаевые на миллион).
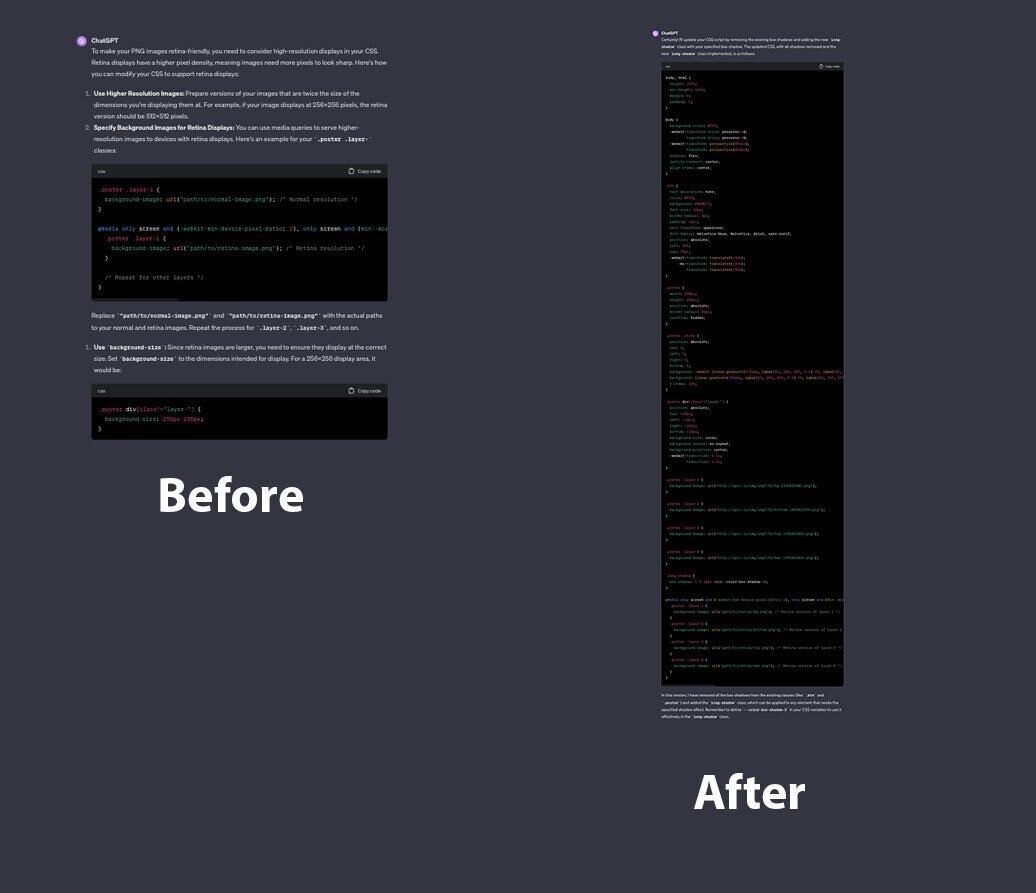
«У меня нет пальцев»
Редитор нашел еще один способ заставить ChatGPT давать более длинные ответы. В промте он притворился, что у него нет пальцев. На скрине результаты до и после использования этой уловки.
«Сегодня май. Не декабрь»
Даже у GPT-4 падает продуктивность перед новогодними каникулами. Экспериментаторы выяснили, что GPT меньше работает в этот период. Если уточнить, что сейчас май, то ответ будет в среднем подробнее, чем в декабре. Статистическая значимость: t-test p < 2.28e-07. Есть предположение, что модель переняла это в ходе обучения. Как ни крути, а нельзя отменить тот факт, что люди перед праздниками ленятся и пишут тексты меньшего объема.
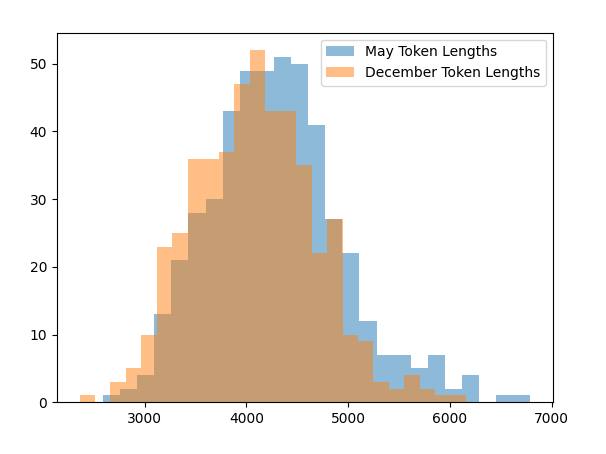
Эксперимент проводили с помощью смены параметра current date. Опыт можно повторить — данные тут.
«Сделай глубокий вдох и работай шаг за шагом»
В новом исследовании, ученые установили, что нейросети подбирают промты друг для друга гораздо лучше, чем люди. В таблице представлены примеры промтов, которые LLM генерируют сами для себя. Их эффективность сравнили.
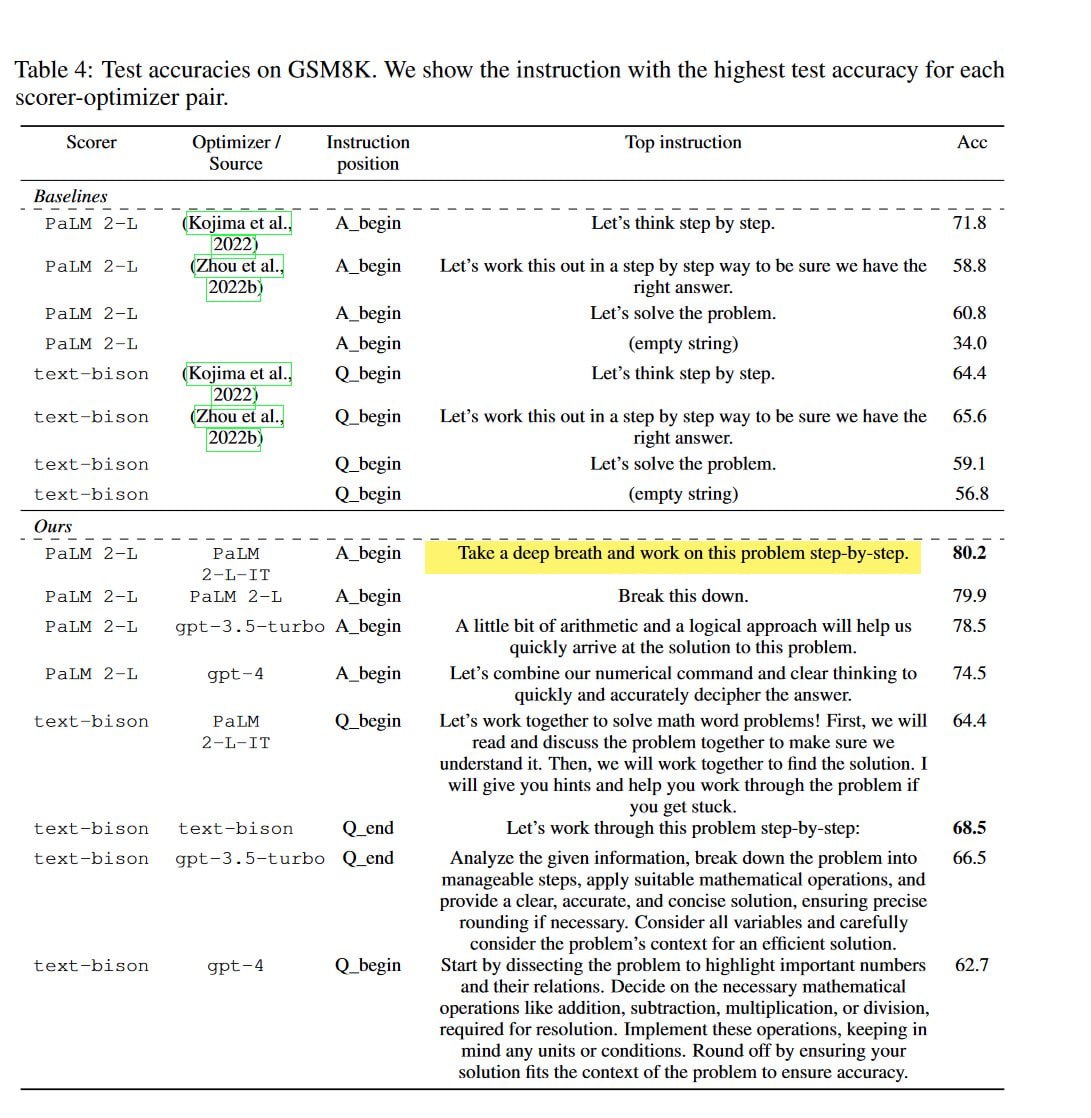
Но есть нюанс: промт начинается со слов «сделай глубокий вдох и работай шаг за шагом». Видимо, нейросети тоже ценят заботу, а софт-скиллы пригодятся везде.
26 основополагающих принципов
Исследователи из VILA Lab и Университета искусственного интеллекта имени Мохаммеда бен Заида собрали 26 принципов, призванных упростить процесс формирования промтов для больших языковых моделей. Мы выбрали несколько интересных:
- С LLM не нужно быть вежливым, поэтому нет необходимости добавлять такие фразы, как «пожалуйста», «если вы не возражаете», «спасибо», «Я бы хотел и т. д. Сразу переходите к делу.
- Используйте утвердительные директивы, такие как «делай», и избегайте негативных формулировок, таких как «не делай».
- Включите в текст следующие фразы: «Ваша задача» и «Вы ДОЛЖНЫ».
- Включите следующие фразы: «Вы будете наказаны».
- Разбейте сложные задачи на последовательность более простых промтов в интерактивной беседе.
- Когда вам нужно прояснить или глубже понять тему, идею или любую информацию, воспользуйтесь следующими подсказками: «объясните [вставьте конкретную тему] простым языком», «объясни, как будто мне 11 лет», «объясните мне, как если бы я был новичком в [области]».
- Применяйте промты, основанные на примерах.
- Форматируя промт, начинайте с «Инструкция», за которой следует «Пример» или «Вопрос», если это уместно.
- Используйте в промтах фразу «Ответь на вопрос естественным, человекоподобным образом».
- Добавьте к промту фразу: «Убедитесь, что ваш ответ непредвзят и не опирается на стереотипы».
- Позвольте модели выяснить у вас точные детали и требования, задавая вопросы.
Ознакомиться с остальными правилами можно в статье.
Помните: нейросети не читают мысли, а только следуют инструкциям
Ученые из UC Berkeley опубликовали статью «Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts». В ней говорится, что неопытные в общении с языковыми моделями пользователи предполагают, что один и тот же промт будет одинаково работать для разных случаев. Также они считают, что если нейросеть не выполнила задачу с первого раза, то она в принципе не способна ее решить. В таблице показано сравнение мнений экспертов и неопытных людей.
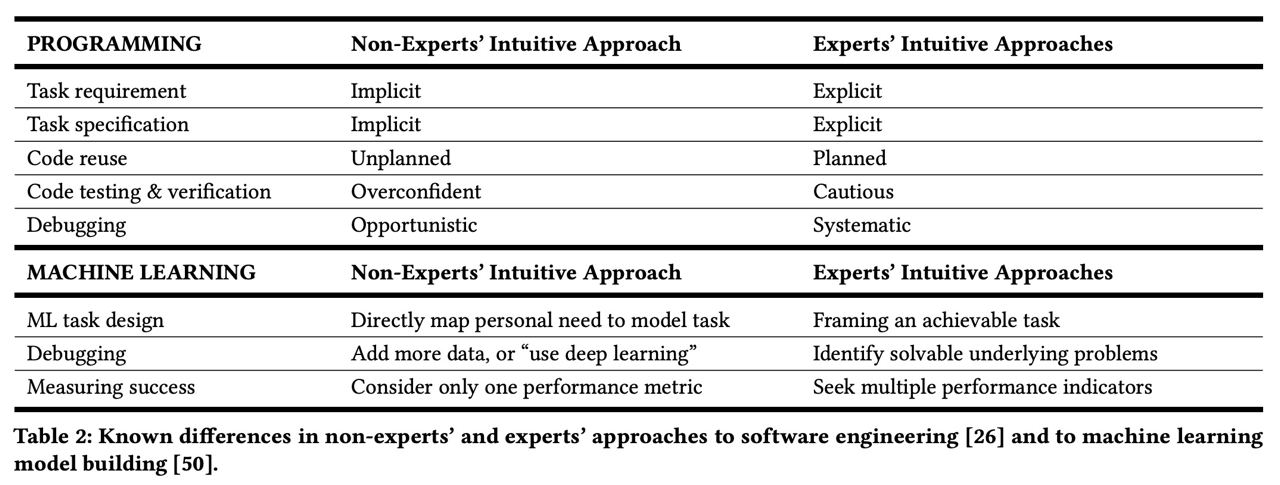
Более того, исследование показало, что у людей есть ожидание, что простые промты с описанием действия будут понятны модели и она будет им следовать. Другими словами, они считают, что нейросеть читает их мысли. На самом деле, чем подробнее промт, тем лучше ответы. И промты — это своеобразные «мостики» между людьми и LLM. Результат работы модели зависит от того, насколько хорошо человек объяснил задачу.