Дипфейки всегда щекотали нервы пользователям интернета. А пик интереса к ИИ-инструментам только усилил тенденцию. Изображения, сгенерированные нейросетями, стали проблемой. Технологические компании пытаются решить вопрос о том, как бороться с неоднозначным использованием инструментов искусственного интеллекта. В нашей статье разбираемся, что придумали техногиганты для маркировки такого контента.

Как поддельные изображения вошли в топ поисковой выдачи Google
В Google не могут защитить свои результаты поиска от поддельных изображений, сгенерированных искусственным интеллектом. Если набрать в поисковике «Tank Man», то в качестве первого результата поиска на платформе появляется фальшивое фото «Tank Man Selfie», сгенерированное нейросетью.

Созданное искусственным интеллектом селфи появляется в выдаче выше по списку, чем оригинальные кадры с человеком, остановившим несколько танков на площади Тяньаньмэнь в 1989 году. Это один из самых известных снимков протестов в мире. Уже сейчас кажется, что искусственный интеллект переписывает историю этой фотографии.

Но не только история пострадала от ИИ-контента. Произведений искусства это тоже касается. В мае система Google позволила сгенерированным изображениям вытеснить работы художника с первых мест в результатах поисковой выдачи. При поиске пользователями Google знаменитого американского художника-реалиста Edward Hopper на первые места в поисковой выдаче выводилась сгенерированная искусственным интеллектом подделка в стиле этого американского художника. Спустя время Google устранил проблему.
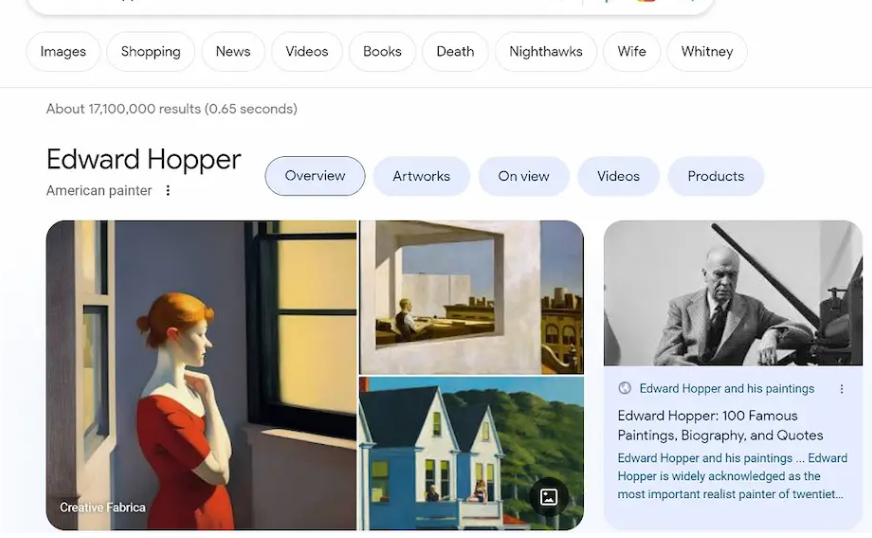
Спустя месяц снова появилась аналогичная проблема, но с другим художником. Если набрать в Google «Johannes Vermee» (это голландский мастер барокко), то в качестве первого результата будет не картина «Девушка с жемчужной сережкой», а ее вариант, сгенерированный нейросетью.

В начале этого года генератор изображений Midjourney использовали для создания фальшивых изображений ареста Дональда Трампа, которые впоследствии завирусились в интернете. Хотя многим было очевидно, что изображения поддельные, Midjourney все же решила принять меры и забанила пользователя, который их создал.

Кстати, им был Элиот Хиггинс, основатель интернет-издания Bellingcat. Он утверждал, что не пытался обмануть или запутать кого-либо, а просто развлекался с Midjourney. И это только несколько примеров шалостей с нейрогенераторами изображений.
Как в фотобанках появляются картинки, сгенерированные нейросетями
За последний год творческая индустрия насытилась такими инструментами, работающими на основе ИИ, как Adobe Firefly и Canva Magic Studio. Они облегчают работу людям с ограниченным опытом в области дизайна. К тому же на помощь приходят стоковые изображения. Компании часто используют их, поскольку они недорогие и доступные. Это снижает необходимость нанимать опытных дизайнеров для создания контента с нуля. Но не всегда на фотостоках лежит авторский материал. Когда только появились нейросети, генерирующие изображения, вопрос не стоял на повестке дня, так как подобные картинки визуально выделялись. Но сейчас уже сложнее увидеть грань. И этим начали пользоваться.
Например, предприимчивый парень из Турции решил взломать систему. С помощью Midjourney он сгенерировал 3 000 фото разных сыров и залил результаты на фотостоки. На этом он заработал 800 долл.
А недавно произошел более громкий случай. Рекламный постер второго сезона сериала «Локи» на канале Disney Plus вызвал споры среди профессиональных дизайнеров. Дело в том, что он, по крайней мере частично, был создан с помощью ИИ. Иллюстратор Катриа Раден отметила, что спиралевидные часы на заднем плане «подают все признаки ИИ, например, вещи случайным образом превращаются в бессмысленные загогулины». Это артефакты, которые иногда оставляют после себя нейрогенераторы изображений. Кстати, фон на иллюстрации Локи, похоже, был взят с идентичного изображения на Shutterstock под названием «Surreal Infinity Time Spiral Space Antique». Несколько программ проверки изображений с помощью искусственного интеллекта (aiornot, illuminarty, huggingface, hive) просканировали картинку и отметили ее как созданное искусственным интеллектом.

Согласно правилам Shutterstock, контент, созданный ИИ, не может быть лицензирован на платформе, если он не создан с помощью собственного инструмента Shutterstock для генерации изображений. Именно таким образом сайт стоковых изображений может подтвердить право собственности на все предоставленные материалы. Shutterstock утверждает, что созданные с помощью искусственного интеллекта стоковые изображения, которые четко обозначены на платформе, безопасны для коммерческого использования, поскольку они обучаются на базе собственной библиотеки стоковых изображений.
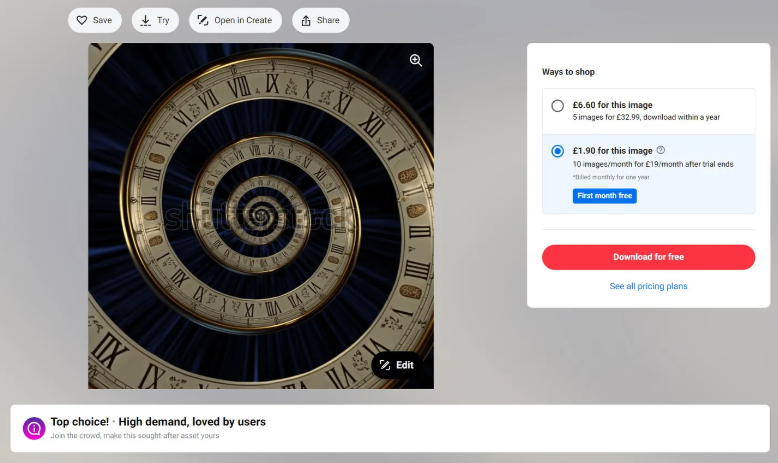
Такие компании, как Adobe и Getty, также продвигают способы коммерческого использования контента, созданного искусственным интеллектом, однако неясно, насколько эти платформы лучше, чем Shutterstock, справляются с модерацией материалов, которые не соответствуют их правилам для авторов.
Будут ли крупные игроки в сфере ИИ разрабатывать защитные меры
В связи с растущей обеспокоенностью общества по поводу неправомерного использования ИИ летом 2023 года OpenAI, Microsoft, Google, Meta*, Amazon, Anthropic и Inflection взяли на себя обязательства по разработке технологий, позволяющих наносить водяные знаки на контент, который сгенерировал искусственный интеллект. Документ опубликован на сайте Администрации президента США.
Цель в том, чтобы сделать такой контент более безопасным и предотвратить дезинформацию и дипфейки, то есть все модели ИИ не должны вводить других в заблуждение относительно подлинности материала. Белый Дом заявил, что водяной знак позволит «процветать творчеству с использованием ИИ, но при этом уменьшит опасность мошенничества и обмана».
Кроме маркировки ИИ-контента, компании также обязались проводить тестирование систем ИИ перед выпуском, инвестировать в кибербезопасность и обмен информацией для снижения рисков.
Почему пока не получается решить задачу детекции сгенерированных изображений (fake image detection)
Суть задачи fake image detection в том, чтобы отличить изображения, сгенерированные нейросетями, от реальных. И как видим, она становится все более актуальной. Но подступиться к ней довольно сложно. Проблема в том, что неясно, как построить систему оценки.
По сути, надо решить задачу бинарной классификации — фейк или реальное фото. Логично, что датасет, на котором будет обучена модель, должен состоять из реальных снимков и фейкового контента. Но на этом шаге начинаются проблемы.
- Во-первых, моделей для генерации артов уже много, постоянно появляются новые. Если обучить нашу модель для детекции на том, что уже есть, то когда выйдет новый ИИ-инструмент, детектор не сработает на него, потому что он обучен на артах конкретных моделей.
- Во-вторых, проблема заключается в балансировании датасета для обучения модели-детектора. Чтобы отличить фейковые арты от реальных картинок, нужно, чтобы они имели отличия по конкретным характеристикам, а в остальном распределении были одинаковыми. Например, можно взять датасет из реальных изображений котов и фейковых картинок собак. Нейросеть обучится отличать их. Но проблема в том, что вне этого датасета работать она вряд ли будет. То есть нам нужно в нем собрать максимальное разнообразие, но данные при этом должны быть похожи между собой.
- В-третьих, модель-детектор фейков должна работать в интернете, в полевых условиях. Но проблема в том, что там изображения меняют: накладывают эффекты, сжимают, меняют формат. Можно добавить в датасет изображения с различными изменениями, но этих методов слишком много и объять все не получится. Сюда добавляются еще снимки, которые были реальны, но их «отфотошопили», и получились «полуфейки».
Какие есть подходы к решению задачи детекции сгенерированных изображений
Из-за перечисленных выше проблем пока не собран единый датасет для модели, которая определяла бы сгенерированные арты. В электронных архивах есть несколько научных работ по этой теме, и в каждой статье датасеты отличаются.
- Detecting Generated Images by Real Images (ECCV-2022)
- DFDT: An End-to-End DeepFake Detection Framework Using Vision Transformer
- Deepfake Video Detection Using Convolutional Vision Transformer
- ResNets for detection of computer generated images
- Think Twice Before Detecting GAN-generated Fake Images from their Spectral Domain Imprints
- Intriguing properties of synthetic images: from generative adversarial networks to diffusion models
- On the Detection of Synthetic Images Generated by Diffusion Models
- Towards Universal Fake Image Detectors that Generalize Across Generative Models
- Pattern Detection in the Activation Space for Identifying Synthesised Content
Стоит отметить, что задача fake image detection похожа на deepfake detection, и как раз по второй теме литературы побольше. Отличие в том, что дипфейки касаются именно картинок с людьми, и модели для их детекции заточены именно на такие изображения. Но некоторые идеи можно задействовать для выявления артов, сгенерированных нейросетями.
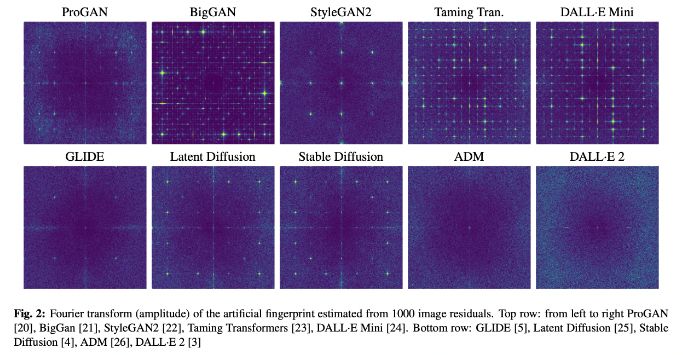
Пока наиболее очевидное решение проблемы — использовать специфичные «отпечатки» (fingerprints), которые оставляют в сгенерированных изображениях все ИИ-модели. Берем картинку, прогоняем ее через фильтры и получаем шумы — некоторые случайные компоненты, которые повторяются.
Сработают ли водяные знаки для идентификации изображений, сделанных нейросетями
Водяные знаки стали одной из наиболее перспективных стратегий идентификации изображений, созданных ИИ. Подобно тому, как физические водяные знаки ставятся на бумажных деньгах для подтверждения подлинности, цифровые водяные знаки призваны отслеживать происхождение изображений в Интернете.
В конце августа компания DeepMind от Google выпустила бета-версию своего нового инструмента для создания водяных знаков SynthID. Система работает, внося тонкие изменения в отдельные пиксели изображений, которые невидимы для человеческого глаза, но алгоритмы могут обнаружить их. Нейросеть-детектор распознает watermark, даже если только часть картинки была сгенерирована. Водяной знак можно будет добавлять к своим артам по желанию.

SynthID работает на основе двух моделей: одна добавляет watermark на картинку, вторая нужна для ее детекции на входном изображении. Водяной знак не виден и не влияет на качество изображения.
Однако, исследователи Университета Мэриленда (США) смогли обойти все существующие методы маркировки контента, созданного ИИ. Сохейл Фейзи и его соавторы изучили, насколько легко недобросовестным субъектам уклониться от попыток нанесения водяных знаков. Он называет это «вымыванием» водяного знака. Помимо демонстрации того, как злоумышленники могут удалять водяные знаки, исследование показывает, как можно добавлять водяные знаки в изображения, созданные человеком, что приводит к ложным срабатываниям.
Как дела обстоят в Китае
В Китае с детекцией сгенерированных изображений пошли по самому простому и одновременно максимально жесткому пути. В январе 2023 года Администрация киберпространства Китая ввела правило о маркировке видео и фото, сделанных с применением технологий глубокого синтеза. Так решили предотвратить замешательство в обществе. Также Китай вводит ответственность за удаление водяных знаков. Более того, граждане страны должны регистрировать учетные записи под собственным настоящим именем, если они хотят воспользоваться нейросетью для синтеза контента. Так можно будет отследить их деятельность.
И этот метод в Китае работает. Уже появился первый подозреваемый, которому грозит до 10 лет тюрьмы. Хун из провинции Ганьсу арестован за использование технологий ИИ с целью создания и размещения в интернете информации без соответствующей маркировки. Он попытался заработать и с 20 аккаунтов в социальной сети Baijiahao распространил новость, которая набрала 15 000 кликов. А потом на нее наткнулись сотрудники киберполиции. Фейковая новость была о том, что погибли 9 человек в аварии с поездом.
Какие компании начали вводить маркировку ИИ-контента
Маркировка ИИ-контента становится все более распространенной практикой. Например, такой практики придерживается TikTok, который объявил, что создатели контента должны самостоятельно маркировать его, если тот сгенерирован нейросетями. На видео будет отображаться соответствующее изображение.
В TikTok утверждают, что не будут наказывать авторов за несоблюдение правила. Но в дальнейшем будет работать автоматическая маркировка. В компании утверждают, что будут использовать собственные технологии для обнаружения контента, созданного ИИ.
Instagram* тоже объявил, что работает над ярлыками для подобного контента. Такие фото будут с уведомлением «создан или отредактирован с помощью ИИ» и дополнительным указанием на нейросеть. Об автоматизации этого процесса пока что ни слова.
Можно ли защитить свои фото
Мы нашли Open Source проект для защиты фото. Группа исследователей разработали инструмент для защиты изображений от вредоносных манипуляций и редактирования нейросетями.
Инструмент добавляет к изображениям незаметные нарушения и помехи, которые не позволяют модели ИИ выполнять реалистичное редактирование. Скачать можно здесь.
Заключение
Чем дальше, тем меньше шансов, что сгенерированные изображения можно будет отличить от реальных. Можно всех обязать внедрить SynthID и маркировку ИИ-контента, но как следить за соблюдением этого правила? Возможно, нам следует привыкнуть к тому факту, что мы больше не сможем надежно идентифицировать изображения, сделанные нейросетями. Проблема еще и в том, что как только мы научимся делать хорошие детекторы фейков, в тот же самый момент начнутся поиски методов обхода — и так будет по кругу.
*Meta, которой принадлежит Instagram, признана в России экстремистской организацией