В конце января хакеры выложили в сеть 45 ГБ исходного кода интернет-гиганта «Яндекс». Хотя сама утечка не содержала данных пользователей, все же можно заглянуть за занавес всех основных сервисов, включая Metrika, которая собирает пользовательскую информацию, и Crypta — технологию поведенческой аналитики «Яндекса». Мы решили поделиться переводом исследования, представленного на выставках Diana Initiative 7 августа, BSides Las Vegas 9 августа и BlackHat 10 августа 2023 года. Автор детально изучил код из утечки «Яндекса» и подробно объяснил все находки из него.

Кодовая база
Код в утечке из «Яндекса» разбит по сервисам. Он написан на смеси русского и английского языков. Используются различные языки программирования, но в основном Python, C++ и YQL (Yandex Query Language, разновидность SQL). Утечка содержала только код, а не настоящий git-репозиторий, в котором можно было бы увидеть историю версий, и несколько блокнотов Jupyter с выведенными данными. Это означает, что нельзя с уверенностью сказать, какие части кода действительно задействованы в настоящее время.
Metrika
Рассмотрим некоторые поля исходных данных, которые регистрирует AppMetrica. Помните, Яндекс заявлял, что собираемые ею данные не персонализированы и очень ограничены? Похоже, что это не так. На рисунке вверху видно, что эта выборка полей попадает в так называемый «анонимайзер». Но ничто в этом уровне детализации не анонимизируется, когда оно попадает на серверы AppMetrica, то есть данные не становятся по-настоящему анонимными.
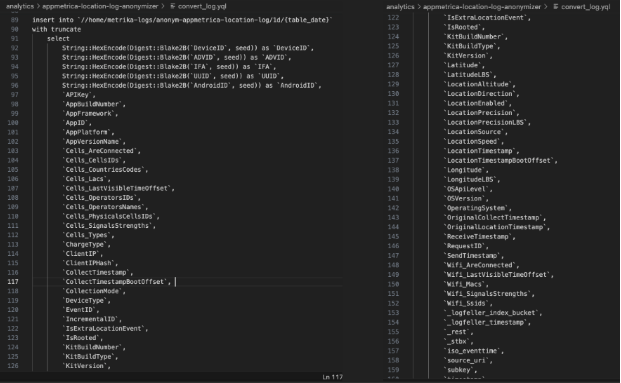
Начнем с того, что уникальные идентификаторы, расположенные в верхней части списка, подвергаются хэшированию. Это хорошо и теоретически позволяет сохранить анонимность, но они все равно будут очень уникальными и, следовательно, однозначно идентифицируемыми. Это позволит легко сопоставлять поступающие данные с другими данными об этом устройстве по мере их поступления, поскольку сервису достаточно хэшировать все входящие идентификаторы и посмотреть, совпадают ли выходные данные. Возможность сохранить конфиденциальность и при этом связать новые данные с существующими — вот главная привлекательность этой стратегии анонимизации.

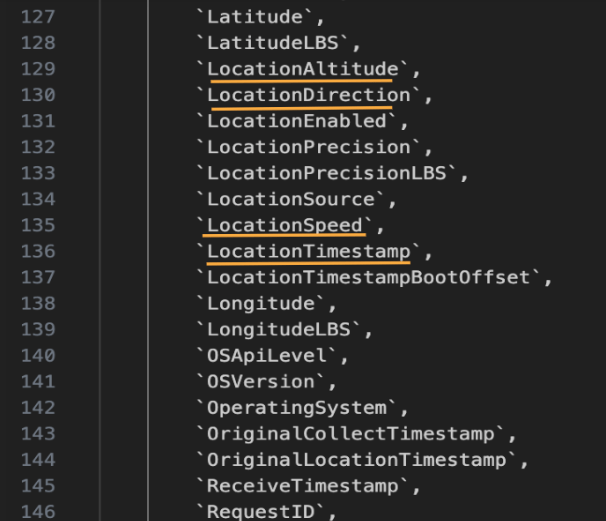
AppMetrica получает очень точные данные о местоположении. В аналитике приложений нередко используются данные о широте и долготе, чтобы команды по развитию и маркетингу могли видеть, где используется приложение. Реже ведется учет высоты, направления и скорости движения пользователя, что в сочетании с временной меткой позволяет получить удивительно точную картину его перемещений. Если только используемое приложение не является фитнес-трекером или чем-то вроде Pokemon Go, то не так уж много случаев, которые оправдывают получение таких данных. Если кто-то использует приложение в самолете, то с помощью этой информации можно увидеть, как высоко летит самолет, в каком направлении, с какой скоростью и, возможно, предсказать, куда он направится в следующий момент. Это кажется излишеством для команды по развитию и маркетингу.
Metrika также содержит код, который позволяет создавать сегменты для целевой рекламы или профили пользователей, используя данные AppMetrica, Data Brokers или загружая свои собственные данные. В первых двух случаях потребители, попавшие в сегмент, не обязательно должны пользоваться продуктом заказчика, он может быть использован для генерации новых лидов.
По мере поступления новой информации социально-демографические характеристики пользователя обновляются при необходимости.
Crypta
Crypta — это сервис поведенческой аналитики Яндекса, создающий демографические сегменты для таргетинга, в частности, Yandex Ads. Он берет данные со всех сервисов Яндекса и объединяет их с выводами, сделанными на основе анализа поведения. Так создаются целостные профили. Отчасти это связано с тем, что Яндекс размещает рекламу во всех своих сервисах. Например, при использовании «Яндекс Навигатора», если пользователь остановился в пробке, Яндекс начнет показывать рекламу.
Вот несколько примеров сегментов, которые генерирует Crypta:
- сегмент «Курильщики», по-видимому, отслеживает пользователей, которые покупают электронные сигареты или табак;
- сегмент «Летние жители» использует геолокационные данные для отслеживания того, у кого из пользователей есть дачи и как часто они их посещают;
- «Путешественники» используют геолокацию для отслеживания того, совершил ли пользователь поездку из своего основного региона (который Crypta уже определила) в другой, а заодно и классифицируют ее как внутреннюю или международную. В этом также помогают данные из электронной почты: так можно отследить, есть ли у пользователя билеты на самолет или подтверждение проживания в гостинице;
- сегмент «АЗС», по-видимому, отслеживает, посещал ли пользователь заправку.
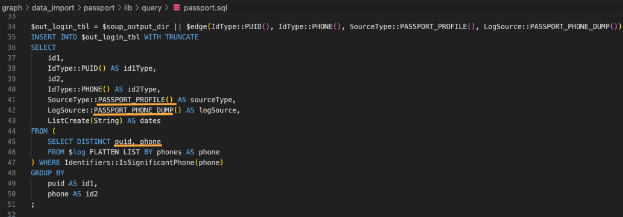
Яндекс использует систему «Паспорт» для создания единого логина, который может входить во все приложения и сервисы. В этой форме используются имя, фамилия и номер телефона. Crypta имеет данные к «Паспорту». Берется идентификатор пользователя и сопоставляется с номером телефона. Есть вероятность, что имя и фамилия также могут быть доступны. Тот факт, что существует источник под названием PASSPORT_PHONE_DUMP, позволяет предположить, что эти телефонные номера извлекаются в больших масштабах.
Другой пример обработки данных в секции графиков — взятие широты и долготы предполагаемого места жительства пользователя, связанного с его идентификатором Yandex, и нанесение их на географический график. Затем он используется для поиска и построения графика соседей этого пользователя и их Яндекс-идентификаторов.
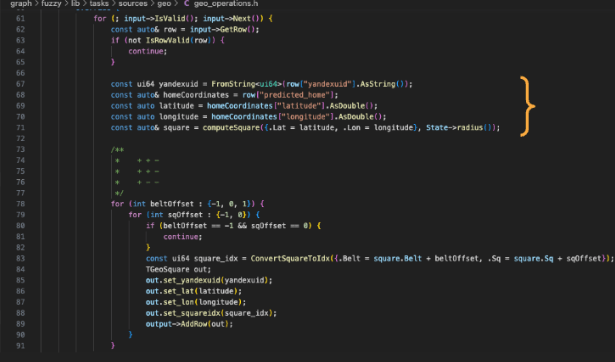
Crypta использует данные о входе в электронную почту, геолокационные данные о местонахождении дома и работы, данные о домохозяйствах. Базовый пример состава домохозяйства, хранящийся в Crypta: идентификатор домохозяйства, размер, пол, наличие пожилых людей, наличие детей.
В профили Crypta интегрируются биометрические данные, полученные, скорее всего, от смарт-динамиков, которые использует интеллектуальный помощник «Алиса». Предполагается, что она может играть с детьми. Crypta использует биометрические данные для идентификации детей и их возрастной категории по голосу, чтобы в дальнейшем составить профиль домохозяйства для использования в рекламе.
Заключение
Утечка кода и его детальное изучение вызывает опасения по поводу объема данных, которыми располагает международный технологический гигант «Яндекс» о своих пользователях. Собранные данные могут рассказать о человеке многое, если их сопоставить и проанализировать с другой информацией, которая у компании уже хранится. Яндекс делает несколько жестов в сторону анонимизации, но они неэффективны, поскольку хэширование используется непоследовательно, и, что более важно, он собирает данные, которые могут легко повторно идентифицировать пользователя.