
Вы не задумывались, для чего Google искусственный интеллект? Для чего все эти победы в го, эксперименты с синтетической музыкой и прозой? Уж конечно не ради имиджа. История беспощадна к бескорыстным изобретателям, печальной памяти Xerox PARC — тому пример. И Google, то есть, простите Alphabet, на эти грабли наступать точно не собирается. У каждого её проекта обязательно есть приземлённая, прагматическая цель. Например, нынче летом она сообщила, что, натравив свою, тренированную на аркадах нейросеть, на управление дата-центрами, сэкономила миллионы долларов на электричестве — и в общем «отбила» покупку ИИ-стартапа DeepMind, за который пару лет назад отдала $600 млн. Такая вот она, высокая наука крупного бизнеса.
К счастью, даже прикрыв главный испытательный полигон, Google Labs, гугловцы не стали принуждать своих учёных выпускать, образно выражаясь, сковородки. И время от времени нам, заинтересованным наблюдателям, перепадают приятные находки, коммерческая ценность которых не очевидна. Весной это была победа над человеком в го (спасибо DeepMind). А на днях всё та же команда сообщила, что научила машину говорить человеческим голосом почти так же хорошо, как сам человек.

Тут, впрочем, стоит сразу послушать. Потому что на мой личный вкус, новый синтезатор говорит не просто на голову лучше всех механических предыдущих, а так же хорошо, как человек: речь его не просто информативна — она приятна для уха! И это многое обещает в перспективе.
Как этого добились? Решив задачу нестандартно. До сих пор голос синтезировался двумя способами. Один: «наговорить на ленту» множество фраз, а потом заставить машину порезать их на слова и фонемы и научить плавно сливать. Так, в частности, «говорят» Siri и Android. Другой способ — параметрический: нужно написать программу (вокодер), синтезирующую фонемы, и заставить её «проговаривать» текст. Оба способа сравнительно легко программируются и требуют сравнительно небольших вычислительных ресурсов, почему и используются широко. К сожалению, качество такого синтеза оставляет желать лучшего: голос при всём желании не спутаешь с человеческим, ибо звучит он отрывисто, без выраженной интонации, всегда одинаково, ну и вообще неестественно.
А гугловцы, повторюсь, пошли другим путём. Они заставили нейросеть синтезировать голос буквально по «пикселям», звуковым квантам, с частотой 16 кГц. То есть никаких фонем, а тем более слов, тут нет: машина буквально рисует сырую звуковую волну, как могла бы рисовать синусоиду, например. А чтобы она знала, что нужно рисовать, её предварительно натренировали на фонотеке, содержавшей записи сотни человек, говоривших несколько суток.
В результате WaveNet — так назвали синтезатор или модель, «придуманную» мозгом DeepMind для синтеза голоса — способна не просто говорить, а копировать интонации и особенности речи любого из своих тренеров — такие, в частности, как причмокивание губами или перевод дыхания. Её можно заставить проговаривать текст с разным выражением, голосом мужским или женским, на разных языках, и даже изобрести собственный уникальный голос.
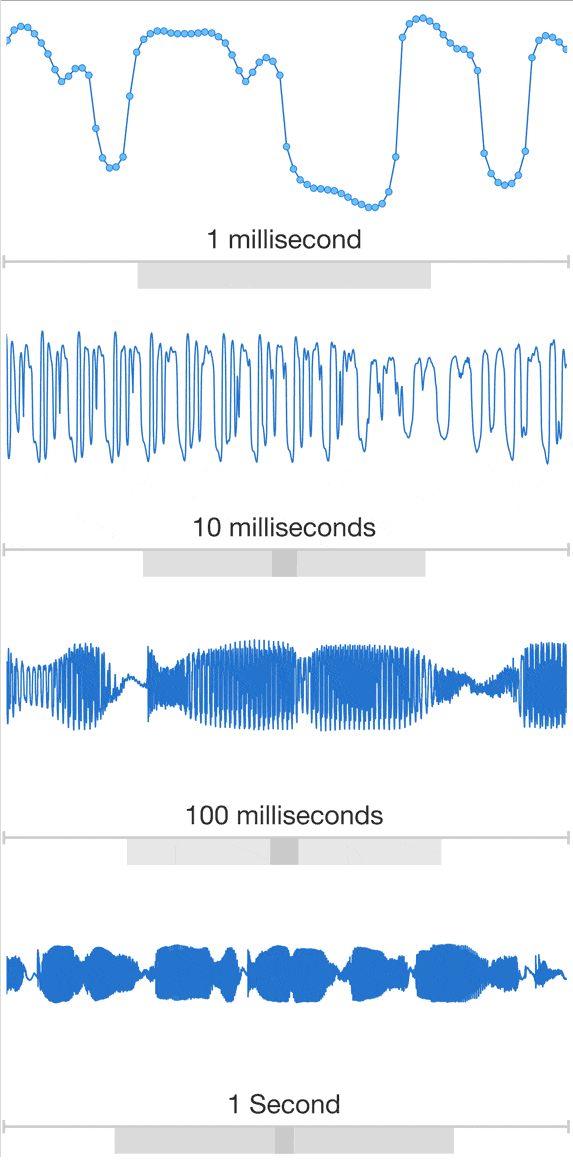
Качество имитации настолько высоко, что средняя оценка, выставленная за натуральность группой слушателей, лишь немного, в десятых долях, уступает оценке голоса живого человека (по 5-балльной шкале, при том, что даже человек 5 баллов не набирает). И последствия рисуются весьма нетривиальные и далеко идущие.
Коммерциализация такой машины — дело, конечно, не одного дня. Пока ещё, чтобы зачитать текст с листа, WaveNet требует всей вычислительной мощи гугловского ИИ. Иначе говоря, на телефоне её не запустишь. Со временем, впрочем, модель наверняка упростят, подогнав под запросы широкого рынка. Но интересней не гадать, когда это случится, а попробовать очертить перспективу, отталкиваясь от самого того факта, что машина научилась говорить неотличимо от человека. Чем и кому это угрожает, чем и кому способно помочь? Кроме тех очевидных миллионов несчастных, которые, в результате травм или болезней, лишены собственного голоса и пока вынуждены говорить голосами синтетическими и одинаковыми — и пожилой дядька Стивен Хокинг, и маленькая девочка.
Так вот на прицеле прежде всего актёры. Спрос на «правильные» голоса в масс-медиа велик. Голос подчёркивает особенности персонажа или продукта. Но теперь, вместо того, чтобы искать наиболее приближенный к желанному идеалу вариант среди людей, режиссёры смогут просто запросить голосовую модель, точно удовлетворяющую нескольким критериям, у Google. И WaveNet прочитает текст с нужной интонацией, ритмом, громкостью, правильно с первого раза и максимально приятно для слушателя.

Отсюда прямо следует вариант появления неестественных голосов, которые будут звучать приятнее натуральных. Красота — парадоксальная штука: мы часто считаем красивым то, чего природа создать не смогла. Так почему и голосу не быть таким же? А значит и реклама, и продающие телефонные звонки, и даже, вероятно, деловые переговоры (через Сеть или с переводчиком), будут озвучиваться не человеком, а машиной. Уверен, кто-нибудь из фантастов эту тему уже прорабатывал. Подскажете?
Далее, новую модель, конечно, возьмут на вооружение мошенники всех сортов — от чистых уголовников до заседающих в штабах политических кандидатов. Представьте себе, как резко способна поменять расстановку сил в предвыборной гонке «случайно утекшая запись» телефонного разговора двух политиков, обсуждающих что-нибудь противозаконное. Для обывателя синтезированные голоса сквозь наложенные помехи будут звучать неотличимо от оригиналов. Но даже и эксперты — смогут ли определить, что запись сфабрикована, что голоса ненастоящие? Найдутся ли в речи, синтезированной «попиксельно», хоть какие-нибудь зацепки, свидетельствующие о подделке? Если интересно, можете попробовать свои силы прямо сейчас — Google опубликовала достаточное количество синтетических фонограмм.
Наконец, что интересно и неожиданно, WaveNet можно заставить работать «задом наперёд» и не только для голоса. Она, например, способна учиться, а потом генерировать весьма интересные (по крайней мере на взгляд непрофессионала: было бы интересно услышать мнение людей с соответствующим образованием) музыкальные пассажи. А «развернув» её, как утверждают авторы, получим беспрецедентно качественную систему распознавания речи. То и другое пока лишь забавные «побочные эффекты». Но какова же мощь основной технологии, если даже её незапланированные свойства таят угрозу для людей творческих профессий!
P.S. В статье использованы графические работы DeepMind, Ashley Rose.